Mine started with selection.
Years ago, working with a PHP-based stock selection system long
before today’s ML ecosystem, I found myself repeatedly returning to
the same uncomfortable realization:
I didn’t actually need accurate return forecasts — I needed a way to
order stocks under uncertainty.
That distinction sounds minor. It isn’t.
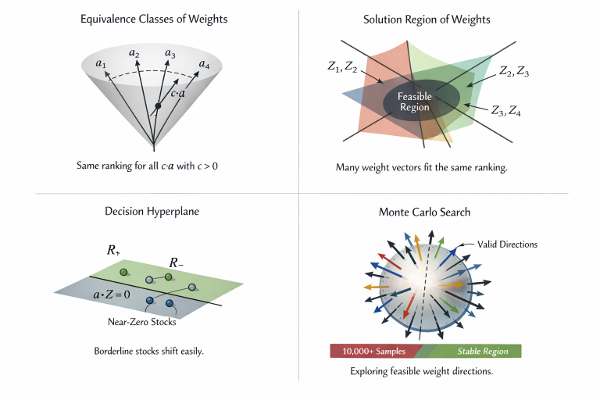
This post is the first in a series of exploratory notes meant to reinterpret
an old z-ranking–based stock selection framework using modern
mathematical ideas: order statistics, ranking geometry, stability, and
noise.
There is no code here. No backtests. No claims of optimality.
This is about conceptual foundations — and about understanding why
certain simple systems keep reappearing across finance, language,
and decision-making, even when theory lags behind practice.
Please read the full note in pdf